
Abstract
In this paper we describe some of the weakness of Convolutional Neural Networks (CNN) and why Capsule Networks are a better alternative to CNNs for developing neurologically inspired machine vision systems. The Capsule Network was invented by Geoffrey Hinton and his fellow researchers at Google Brain to address the deficiencies they saw with current CNN techniques. We compare both technologies and show why the Capsule Network is a more principled algorithm that may allow machine vision to progress further in the machine learning community.
Background
CNNs have shown superhuman performance in image classification competitions like ImageNet where people compete to develop new network architectures capable of classifying different images. Due to the nature of CNNs, they are able to pick apart statistical anomalies from the data that are unobservable to the human eye. However, CNNs operate in a manner completely different from how humans identify images.
The same properties that make CNNs excel at ImageNet also make them extremely easy to fool. Recall that CNNs utilize positionally invariant feature detectors to great effect. However, they have no way of dealing with relationships between different features other than coarse positional encoding. In fact, every time a CNN uses max pooling they lose positional encoding information. To understand why that can be an issue consider the following example.
One of the major problems with max pooling is that it loses a lot of the spatial information that exists from non-maximum activations. By only taking into account the activations with maximum activations, the CNN is throwing away a lot of the positional information of the image. This can lead to disastrous results when relationships between different detect features have to be recognized as part of the classification process.
“The pooling operation used in convolutional neural networks is a big mistake and the fact that it works so well is a disaster.
If the pools do not overlap, pooling loses valuable information about where things are. We need this information to detect precise relationships between the parts of an object. Its true that if the pools overlap enough, the positions of features will be accurately preserved by “coarse coding” (see my paper on “distributed representations” in 1986 for an explanation of this effect). But I no longer believe that coarse coding is the best way to represent the poses of objects relative to the viewer (by pose I mean position, orientation, and scale).
I think it makes much more sense to represent a pose as a small matrix that converts a vector of positional coordinates relative to the viewer into positional coordinates relative to the shape itself. This is what they do in computer graphics and it makes it easy to capture the effect of a change in viewpoint. It also explains why you cannot see a shape without imposing a rectangular coordinate frame on it, and if you impose a different frame, you cannot even recognize it as the same shape. Convolutional neural nets have no explanation for that, or at least none that I can think of.”
– Geoffrey Hinton
The problem of associating many smaller parts to form a greater whole is not compatible with the CNN architecture. Humans can naturally associate smaller objects to form larger objects. We know instinctively that when we see two eyes, a nose, and a mouth in precise orientations it forms a face. This type of association of various smaller objects to form a larger whole is incompatible with the CNN architecture because there is no method to handle this type of association.
CNNs also do not generalize well to different angles of the same object. The traditional way to handle different view angles for a CNN is to train the network with every possible view angle. Not only is this extremely inefficient, it usually cannot be done in a scalable manner. A CNN trained on an upright image of a cat will not recognize the same picture if flipped upside down.
Inspiration
Hinton has been working on the Capsule Network idea for over 40 years. He was originally inspired by image rendering computer software that allowed computers to render objects with the appropriate pose and orientation of various smaller objects to form a larger whole. Computer rendering software could create complex 3D visualization purely using mathematics. This led Hinton to believe that the human mind was performing some complex mathematics on a grander scale in order to visualize the world.
Hinton’s theory was that the human perception was intricately tied to the pose (rotation and translation) of an object. His theory is that when humans see lower level objects such as eyes, nose, or mouth we intrinsically develop a natural vector orientation for those objects based on a rectangular coordinate system. This allows us to recognize the spatial orientation of that particular object. When we need to combine lower level objects to form a higher level object (i.e. a face), the lower level objects (i.e. eyes, nose, mouth) have to fit a certain pattern. Hinton’s theory is that our brains have a latent representation of higher level objects and that when we perceived the world we are matching what we see to these internal representations of higher level objects. This is a complex idea and is beyond the scope of this paper. Hinton explains this view in his interview with Andrew Ng found on Coursera [Ref 1].

Figure: 3D Software Rendering of Iron Man Helment
The Capsule Network addresses many of the issues of the CNN by incorporating elements that allow the network to:
- uses pose (rotation and translation) information within an image,
- associate smaller parts to a greater whole, and
- handle multiple view angles of the same object without retraining
In order for Capsule Networks to perform all of these goals, it must have a more flexible and extensive architecture capable of supporting all of these desired features. Hinton realized this, which is why he built the Capsule Network using a more malleable mathematical representation than than the CNN. In order to properly understand the differences between a CNN versus a Capsule Network we have to look at the mathematics behind each architecture.

Table 1: CNN vs Capsule Network equations [Ref 2]
Affine Transformation
Transforms the incoming vector 



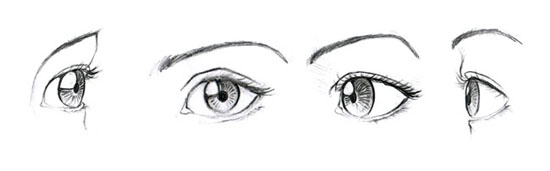
Figure: Eyes with different orientations: Humans instinctively know that the orientation of the eyes implies a certain facial orientation.
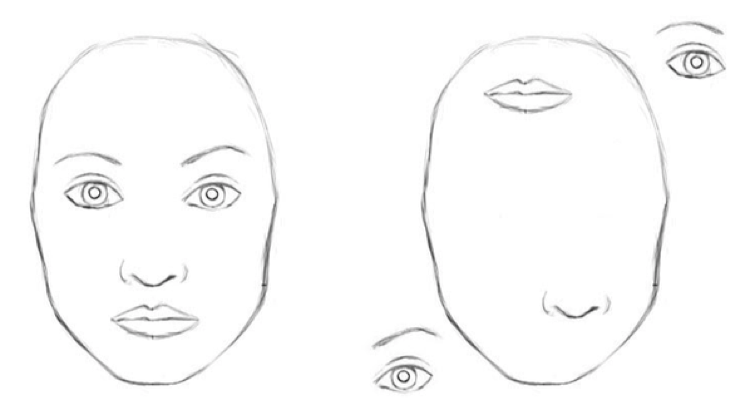
Figure: Facial projections: The affine transformation attempts to project the lower level objects (i.e. eyes, mouth, or nose) onto a higher level vector representing a face.
Each 

Weighting & Sum
This is a routing step where we need to decide where lower level features
In Hinton’s approach the “coupling” weights 



Figure: Capsule Routing: The lower level features are routed to the capsule representing a face. When all the vectors are in proper alignment, it provides strong evidence that a face exists.
The coupling process of calculating the 

Figure: Routing algorithm represents a single forward pass of a Capsule Network
The variable 
This is the essence of how routing by agreement works. The routing algorithm adjusts the variable
CNNs read in scalar inputs and produces scalars outputs representing how well a feature detector matches the data from the previous layer. In contrast Capsule Networks read in vector inputs and produces vector outputs. Vectors have the ability to encapsulate much more information. The key idea is that the vectors outputs of a Capsule Network have the capability of including information regarding pose information if trained properly whereas CNNs do not have the capability of doing the same.

Figure: Capsule Network Visual Representation [Ref 5]
Summary
Capsule networks provide a much more malleable mathematical framework for representing associations between lower level features and higher level features. It is a much more elegant way to handle spatial, pose, and orientation of detected features. Because it routes information to higher level capsules instead of discarding them along the way, Capsule Networks may provide more robust methods for handling image processing than standard CNNs. Hinton’s work has already shown that Capsule Networks have achieved state of the art classification accuracies and are more robust against white pixel attacks than CNNs. Capsules are also a much more intellectually satisfying design that mimics the human’s visual cognitive abilities than CNNs. This tutorial was designed to provide a high level understanding of the Capsule Network. For a more detail tutorial on how Capsule Networks work see Max Pechyonkin’s & and Aurélien Géron’s explanations [Ref 8,9].
References
- A. Ng, “Interview with Geoffrey Hinton,” Neural Networks and Deep Learning. https://www.coursera.org/lecture/neural-networks-deep-learning/geoffrey-hinton-interview-dcm5r
- G. Serif, “A Simple and Intuitive Explanation of Hinton’s Capsule Networks,” Medium Toward Data Science. Aug 22, 2018. https://towardsdatascience.com/a-simple-and-intuitive-explanation-of-hintons-capsule-networks-b59792ad46b1
- G. Hinton, S. Sabour, N. Frosst, “Matrix Capsules with EM Routing,” International Conference Representation Learning (ICRL). 2018. https://openreview.net/pdf?id=HJWLfGWRb
- S. Sabour, N. Frosst, G. E. Hinton, “Dynamic Routing Between Capsules”, Cornell University. ArXix.org
- M. Ross, “A Visual Representation of Capsule Network Computations,” Medium. Nov 14, 2017. https://medium.com/@mike_ross/a-visual-representation-of-capsule-network-computations-83767d79e737
- F. J. Huang, Y. LeCun, “NORB Object Recognition Dataset,” Courant Institute, New York University. 2005. https://cs.nyu.edu/~ylclab/data/norb-v1.0-small/
- A. Karpathy, T. Leung, G. Toderici, R. Sukthankar, S. Shetty, L. Fei-Fei, “Large-scale Video Classification with Convolutional Neural Networks,” IEEE Conference on Computer Vision and Pattern Recognition. 2014. https://ieeexplore.ieee.org/document/6909619
- M. Pechyonkin, “Understanding Hinton’s Capsule Networks,” https://pechyonkin.me/capsules-1/
- A. Géron, “Capsule Networks – Tutorial,” YouTube. https://www.youtube.com/watch?v=pPN8d0E3900
